Установка Ollama в Linux и Docker-контейнер
В мире домашних хостингов и умных домов всё больше устройств и сервисов требуют умных решений для управления и автоматизации. Локальные LLM позволяют интегрировать искусственный интеллект прямо в вашу домашнюю сеть. Это особенно важно для безопасности и конфиденциальности при работе с личной информацией умного дома. К тому же вы получаете бесплатный доступ к API, который работает автономно и без ограничений, позволяя создавать гибкие и мощные сценарии автоматизации именно под ваши нужды.
Предварительные требования
Предполагается что вы уже имеете:
- Debian или Ubuntu Server, в данной статье будем использовать последнюю версию Ubuntu 25.10
- Базовые представления о командной строке Linux и SSH
- Установленный Docker Compose
- Дискретную видеокарту Nvidia не ниже чем RTX 1060. Скорей всего аналогичные шаги будут актуальны для видеокарт Radeon
На менее мощных видекартах или вообще без видеокарты тоже получится попробовать, смотрите в конце статьи какие модели можно выбрать для этих случаев.
Если у вас пока нет отдельного сервера с видеокартой, то вы можете запустить Ollama на своем рабочем компьютере, как это сделать смотрите в конце статьи.
Проверка драйверов
Для статьи будем использовать недавно вышедшую RTX 5060 ti, для которой Nvidia буквально на днях выпустила драйвер для Linux. По этой же причине используем Ubuntu 25.10 с последней доступной версией ядра.
Проверьте, может быть у вас уже установлен драйвер Nvidia командой: nvidia-smi
Если утилита не найдена, то установите ее из предложенных вариантов, например последнюю версию на данный момент (осень 2025г.) и попробуйте снова.
sudo apt install nvidia-utils-580-serverЕсли утилита выдает ошибку или в таблице внизу написано Not Supported, то тут два варианта:
- ваша видеокарта слишком старая и уже не получит поддержку драйверов
- ваше видеокарта слишком новая, как в нашем случае, то может помочь установка свежих драйверов
Установка драйверов
Подготовка
Обновление системы:
sudo apt update
sudo apt upgrade -yУстановка необходимых пакетов:
sudo apt install build-essential dkms linux-headers-$(uname -r) software-properties-commonОтключение Nouveau (встроенный открытый драйвер NVIDIA), чтобы он не мешал:
Откройте указанный файл
sudo nano /etc/modprobe.d/blacklist-nouveau.confДобавьте в этот файл параметры
blacklist nouveau
options nouveau modeset=0Обновите initramfs и перезагрузитесь
sudo update-initramfs -u
sudo rebootУстановка
Проверка доступных драйверов
sudo ubuntu-drivers list --gpgpuВы увидите примерно такие варианты:
nvidia-driver-580-server-open, (kernel modules provided by linux-modules-nvidia-580-server-open-gene ric)
nvidia-driver-580-server, (kernel modules provided by linux-modules-nvidia-580-server-generic) nvidia-driver-580-open, (kernel modules provided by linux-modules-nvidia-580-open-generic) nvidia-driver-580, (kernel modules provided byУстановите самый последний драйвер и перезагрузитесь
sudo ubuntu-drivers install --gpgpu
sudo apt install nvidia-utils-580-server
sudo rebootПосле загрузки проверьте информацию о видеокарте командой nvidia-smi. Если все прошло успешно в таблице должна быть примерно такая информация:
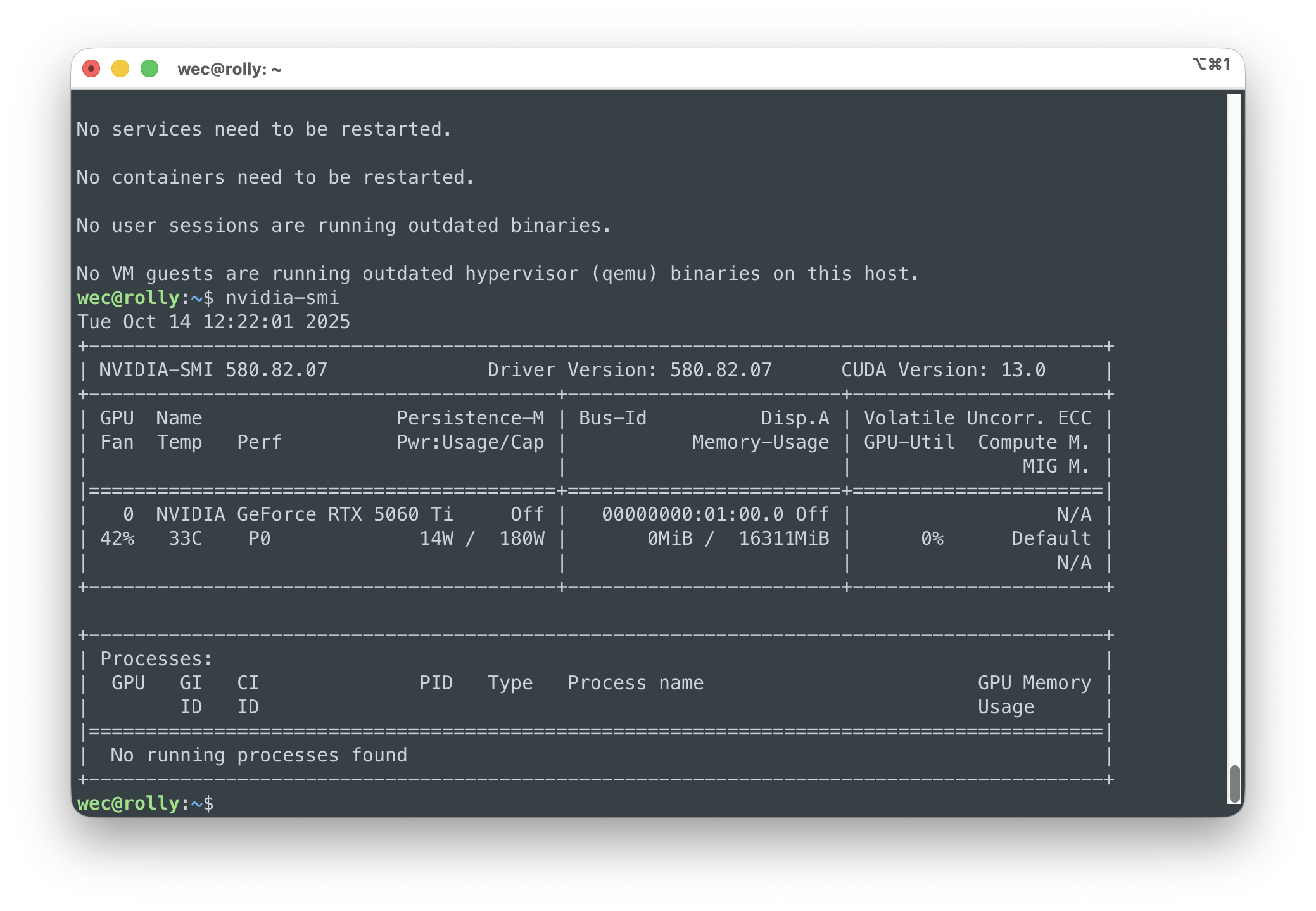
Установка Ollama в Linux или в Docker?
Установка Ollama в Linux более простая в отличии от установки в Docker, т.к. не требует установки дополнительной прослойки для проброса видеокарты в контейнер. Оба варианта одинаково хороши и зависят только от вашего желаения и навыков.
По нашим тестам и замерам производительность Ollama чуть-чуть выше в Docker-контейнере, видимо из-за каких-то оптимизаций и тонких настроек.
Установка Ollama в Linux
curl -fsSL https://ollama.com/install.sh | shВсе! После завершения установки Ollama готова к работе. Проверьте работу загрузив какую-нибудь модель, например gpt-oss:20b — размер 14GB. Для быстрого теста можно выбрать минимальную модель, например gemma3:270m, но она может слишком быстро отработать и вы не успеете увидеть нагрузку. Как выбрать модель описано в конце статьи.
ollama run gpt-oss:20b --verboseПосле загрузки и запуска модели введите любой запрос, во время выполнения запроса откройте второй терминал и командами nvidia-smi и htop посмотрите загрузку видеокарты и процессора. Оптимально подходящая модель должна полность выполняться на видеокарте и практически не использовать оперативную память и процессор.
Установка Open WebUI
Для комфортной работы с LLM рекомендуем установить веб-интерфейс в виде чата, как у облачных нейро-сервисов.
Для того чтобы Ollama была доступна из Docker-контейнера нужно внести небольшие изменения в конфигурацию. Остановите сервис и откройте файл конфигурации:
sudo systemctl stop ollama
sudo nano /etc/systemd/system/ollama.serviceИ добавьте строку в секцию [Service]
Environment="OLLAMA_HOST=0.0.0.0"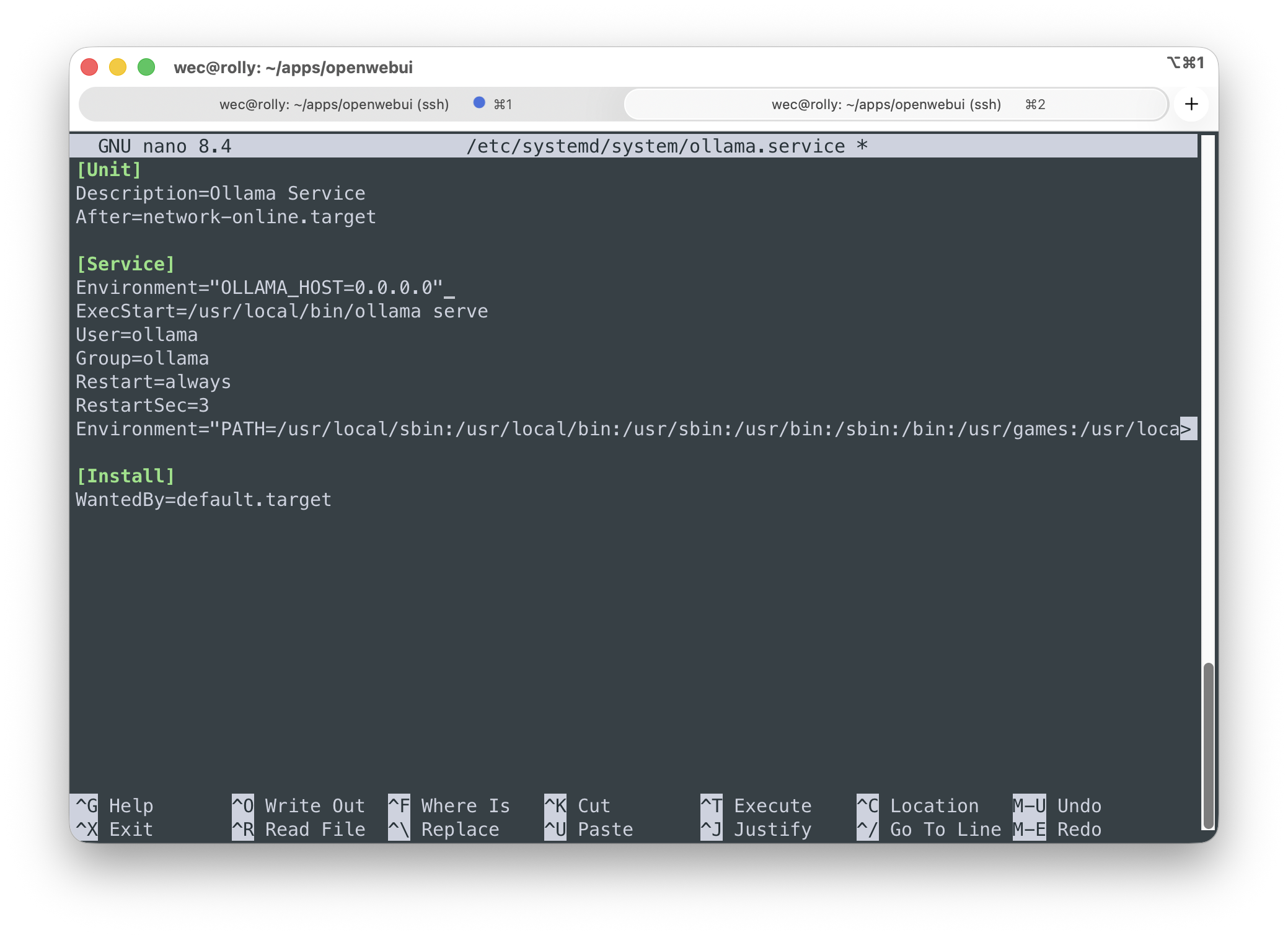
Запустите сервис Ollama
sudo systemctl start ollamaЕсли возникает ошибка
Warning: The unit file, source configuration file or drop-ins of ollama.service changed on disk. Run 'systemctl daemon-reload' to reload units., то выполните требуюмую команду:systemctl daemon-reload
И проверьте, перейдя в браузере по адресу http://<ip_вашего_сервера>:11434. На странице вы должны увидеть Ollama is running.
Создайте папку open-webui, c файлом docker-compose.yml внутри, вставьте содержимое и запустите контейнер. При неоходимости поменяйте порт 3000 на любой другой, если он у вас уже занят.
mkdir open-webui && cd open-webui
nano docker-compose.yml
docker compose up -dФайл docker-compose.yml
services:
open-webui:
image: 'ghcr.io/open-webui/open-webui:main'
restart: always
container_name: open-webui
volumes:
- './data:/app/backend/data'
extra_hosts:
- 'host.docker.internal:host-gateway'
ports:
- '3000:8080'В браузере перейдите по адресу http://<ip_вашего_сервера>:3000 и создайте учетную запись. Это локальная учетная запись, подтверждение email не нужно. Так же в дальнейшем вы можете создать сколько угодно учетных записей для своих друзей и родственников.
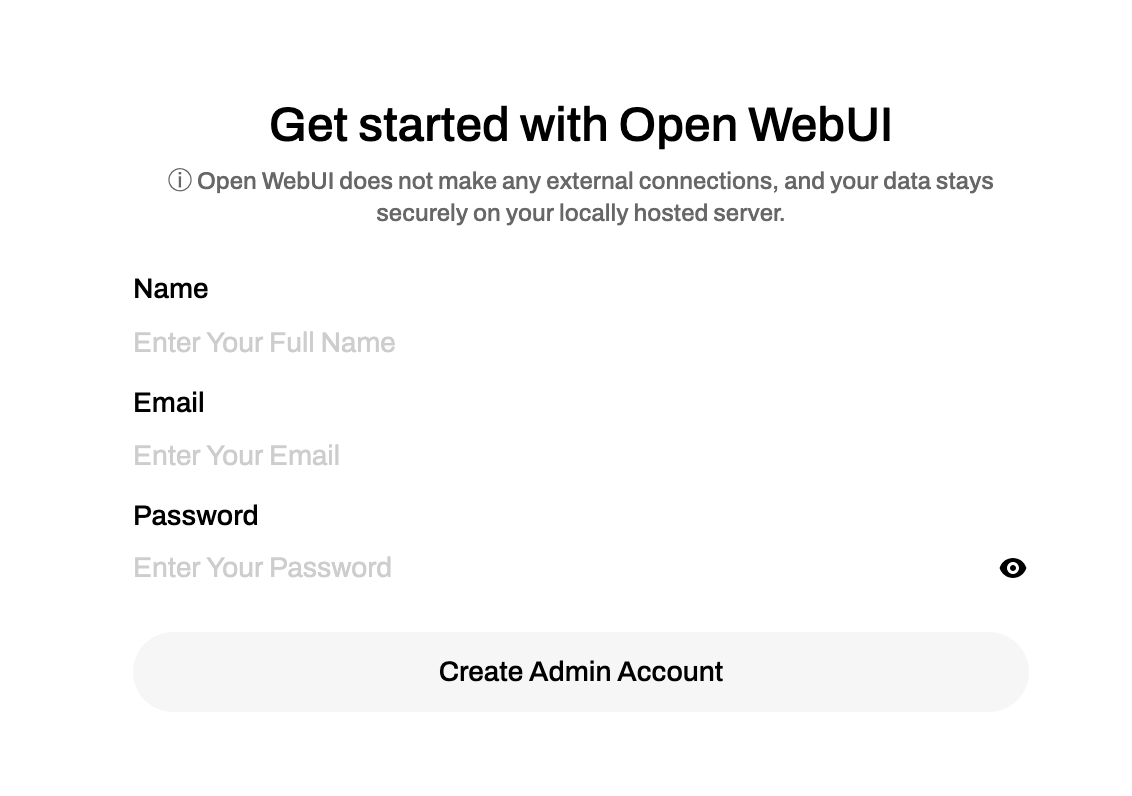
После входа, слева вверху в списке вы можете увидеть список ваших зашруженных моделей, выберите любую и попробуйте в чате пообщаться с моделью.
Если вы загружали модели командой ollama pull или ollama run, но в Open WebUI ее не видно, то проверьте настройки подключения. В Open WebUI левом нижнем углу нажмите на ваш аватар, выберите Admin Panel, перейдите в Settings → Connections (или по адресу http://<ip>:3000/admin/settings/connections) и нажмите на иконку Шестеренки напротив пунка Manage Ollama API Connections.
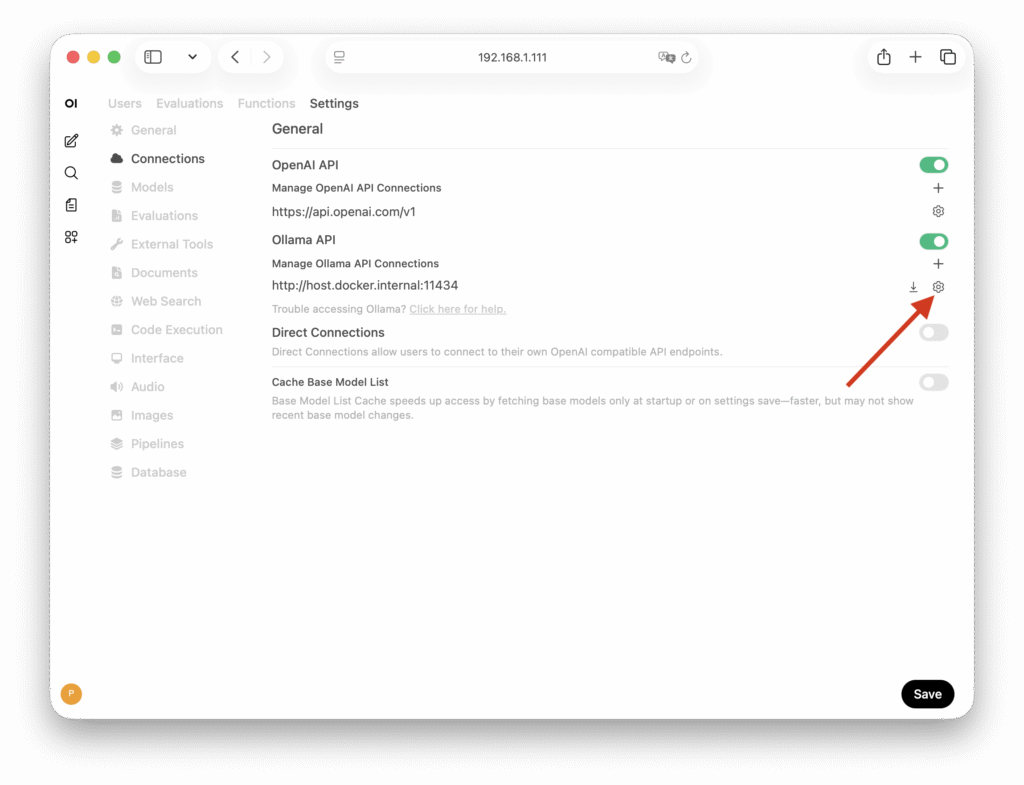
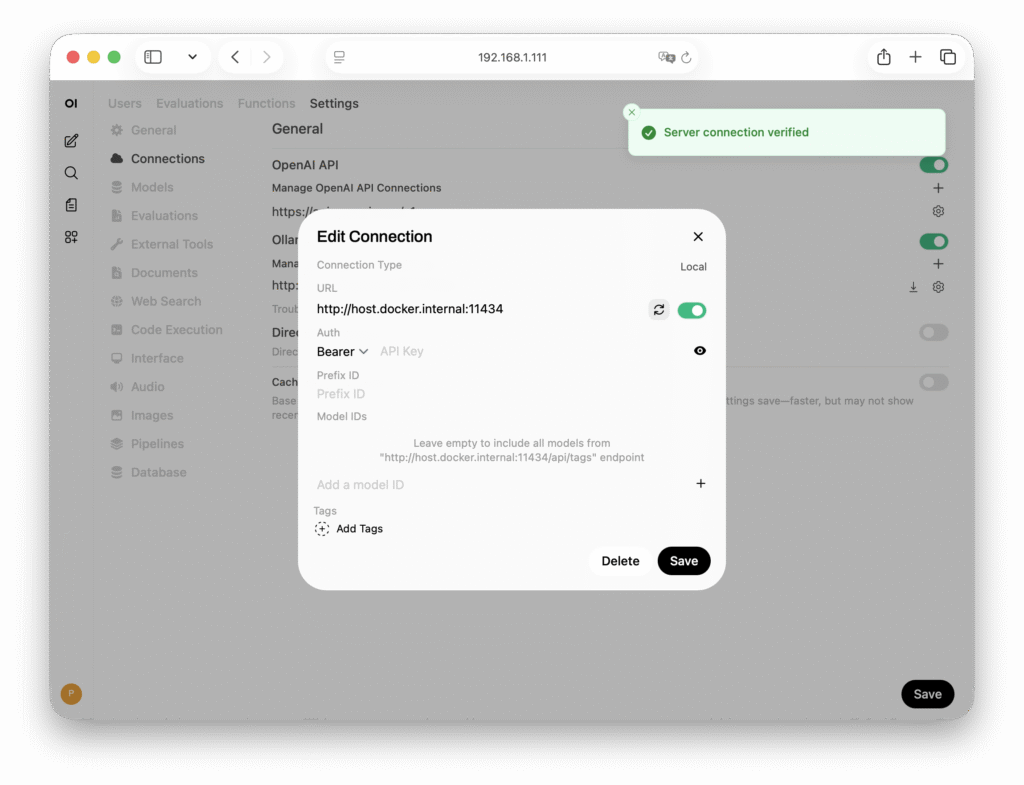
Проверьте соединение нажав на иконку Обновления. Если соединение недоступно, то попробуйте вместо http://host.docker.internal:11434 ввести http://<ip_вашего_сервера>:11434.
Удаление Ollama
Если вы проверили работу Ollama, но решили запустить ее в Docker, то обязательно удалите из Linux.
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service
sudo systemctl daemon-reload
sudo rm $(which ollama)
sudo rm -r $(which ollama | sed 's/bin/lib/')
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
rm -rf ~/.ollamaУстановка Ollama в Docker-контейнер
Для полноценной работы GPU в контейнере для начала необходимо установить набор иструментов от Nvidia.
Для видеокарт от Radeon существует аналогичный набор иструментов под названием
amd-container-toolkit, но т.к. у нас в данный момент нет подходящей видеокарты, ничего про него сказать не можем:(
NVIDIA Container Toolkit
Добавление репозитария Nvidia.
Ниже идут длинные команды, они разделены пустой строкой: в первом случае две команды, а во втором четыре. Пожалуйста копируйте внимательно, не разделяя команды на части.
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listОбновите пакеты и установите пакеты
sudo apt-get update
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo apt-get install -y nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
sudo reboot
Установка Ollama и Open WebUI
Создайте новую папку с файлом docker-compose.yml
mkdir ollama && cd ollama
nano docker-compose.yml
docker compose up -dФайл docker-compose.yml
services:
ollama:
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities:
- gpu
volumes:
- ./ollama:/root/.ollama
ports:
- 11434:11434
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:latest
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
volumes:
- ./open-webui:/app/backend/data
depends_on:
- ollama
ports:
- 3000:8080
environment:
- 'OLLAMA_BASE_URL=http://ollama:11434'
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stoppedВ браузере перейдите по адресу http://<ip_вашего_сервера>:3000, создайте учетную запись, слева вверху выберите модель и напишите в чат любой запрос. Во время выполнения запроса в терминале запустите утилиты htop и nvidia-smi обращая внимание на то чтобы максимальная нагрузка была на видеокарту, а не на процессор.
Установка в Windows или macOS
В Windows обновите драйвера для вашей видеокарты до последней версии и скачайте Ollama с официального сайта. Это приложение сразу предоставляет минимальный интерфейс чата и возможность загрузки моделей без консоли, но и все консольные команды тоже доступны.
Если у вас установлен Docker, то вы так же можете установить Open WebUI по инструкции выше. Но для того чтобы Docker-контейнер увидел Ollama перейдите в настройки и включите доступ по IP-адресу: Settings → Expose Ollama to the network. Так же эта настройка открывает доступ к API внутри локальной сети, который вы можете использовать в интеграции Home Assistant.
Выбор моделей
На сайте Ollama вы можете найти тысячи моделей, для простоты выбора рекомендуем скачивать самые популярные. Выбирайте модели в зависимости от объема памяти (VRAM) видеокарты, очень примерно можно ориентироваться на размер модели, который указан на сайте, но не гарантирует что она поместится в память вашей видеокарты. Если модель не помещается в VRAM, то Ollama может частично или полностью перести ее в оперативную память и распределить нагрузку на процессор вместо видеокарты, что замедляет обработку и делает модель не эффективной.
На странице почти каждой популярной модели вы можете найти ее «сжатую» версию с разной степенью квантанизации, обычно отмечаются суффиксом q4, q8. Обозначение после двоеточия (16b, 20b и т.п.) означает размер модели по количеству параметров (16 миллиардов, 20 миллиардов), чем больше параметров, тем более «глубокая» модель, способная хранить больше информации и обычно выдаёт более точные ответы, но при этом требует больше памяти и вычислительных ресурсов.
Квантизация модели – это «сжатие» её памяти, заменяя точные десятки цифр на простые “чётные” числа, чтобы она занимала меньше места и работала быстрее, но становилась менее точной.
Выбор моделей зависит от ваших потребности и мощности видеокарты, для простых вычислений типа управления умным домом подойдут маленькие модели до 1b, для обработки текста, изображений и общения через чат модели от 8b.
- gpt-oss:20b — на данный момент самая оптимальная и качественная модель, требуется примерно 16gb VRAM
- deepseek-r1 — есть варианты с разным количеством параметров, самая маленькая deepseek-r1:1.5b может даже работать на CPU
- gemma3 — так же множество вариантов, начиная от 270 миллионов (gemma3:270m) параметров, которая может запускать даже не очень слабом железе. Может пойдойти для простого управления автоматизациями умного дома
- qwen3 — тоже не плохая модель, начиная с 600m
Управление моделями
Через терминал
- Скачивание и обновление, например
ollama pull qwen2.5-coder:7b - Список загруженных моделей:
ollama list - Удаление моделей, например:
ollama rm qwen2.5-coder:7b
Через Open WebUI
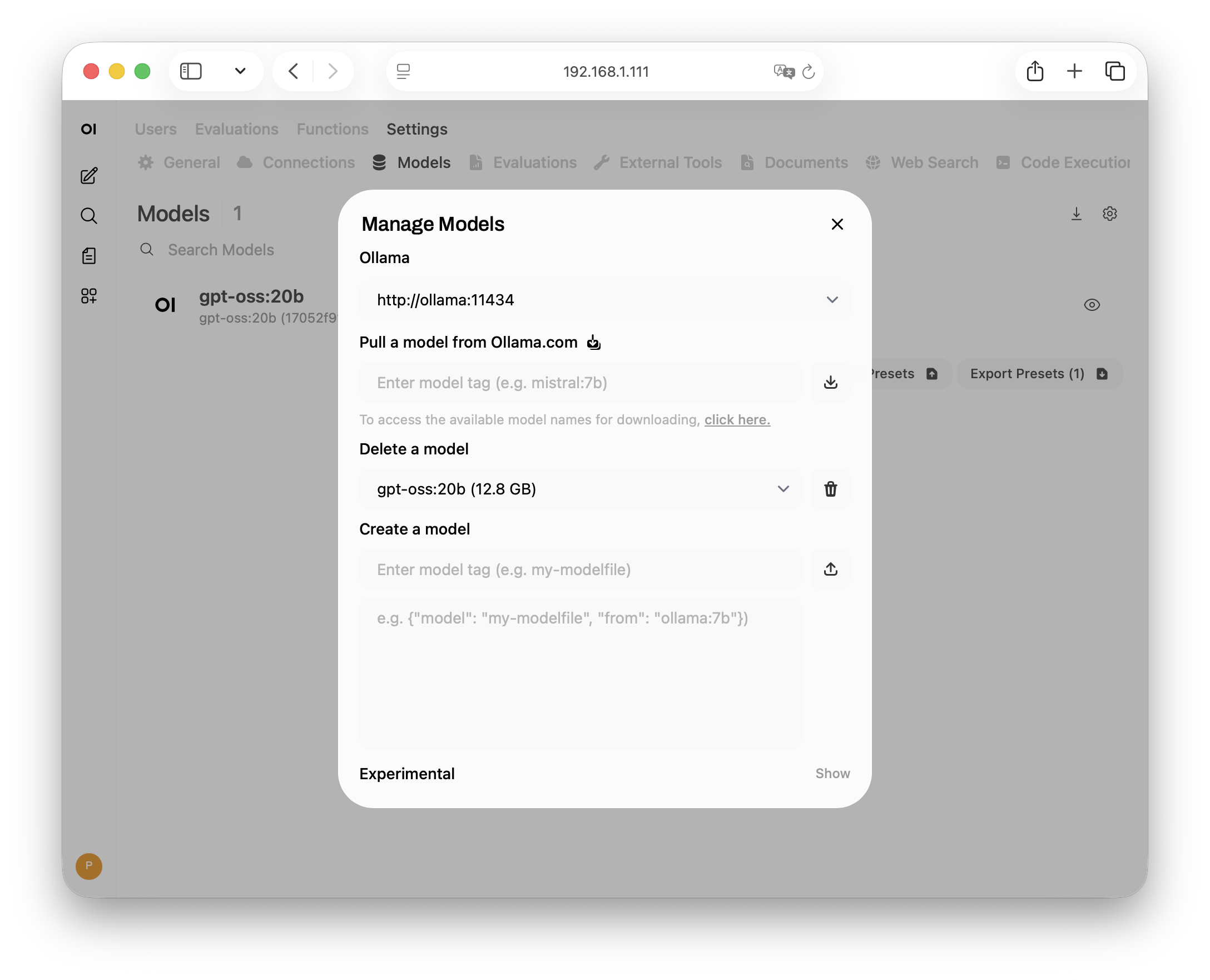
Слева внизу нажмите на аватар, в меню выберите Admin Panel, перейдите в Settings → Models или по адресу http://<ip_вашего_сервера>:3000/admin/settings/models и нажмите справа на иконку Скачивания. В данном окне можете скачивать модели вписав название в соответствующее поле и удалять выбирая из списка.